
DeepSeek has gained recognition within the AI neighborhood with its newest fashions, DeepSeek R1, DeepSeek V3, and DeepSeek R1-Zero. Every mannequin gives distinctive capabilities and is designed to deal with completely different AI purposes. DeepSeek R1 focuses on superior reasoning duties, using reinforcement studying to enhance logical problem-solving abilities. In the meantime, DeepSeek V3 is a scalable pure language processing (NLP) mannequin, leveraging a Combination-of-Specialists (MoE) structure to handle numerous duties effectively. Alternatively, DeepSeek R1-Zero takes a novel method by relying fully on reinforcement studying with out supervised fine-tuning.
This information offers an in depth comparability of those fashions, exploring their architectures, coaching methodologies, efficiency benchmarks, and sensible implementations.
DeepSeek Fashions Overview
1. DeepSeek R1: Optimized for Superior Reasoning
DeepSeek R1 integrates reinforcement studying methods to deal with advanced reasoning. The mannequin stands out in logical deduction, problem-solving, and structured reasoning duties.
Actual-World Instance
Enter: “In a household tree, if Mark is the daddy of Alice and Alice is the mom of Sam, what’s Mark’s relation to Sam?”
Anticipated Output: “Mark is Sam’s grandfather.”
DeepSeek R1 effectively processes logical buildings, making certain its responses are each coherent and correct.
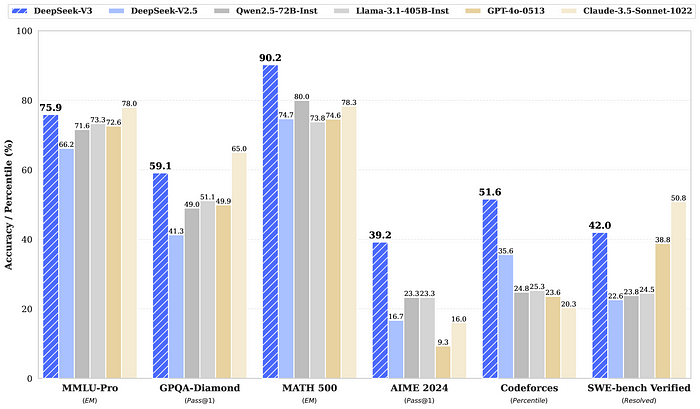
2. DeepSeek V3: Normal-Goal NLP Mannequin
DeepSeek V3, a flexible NLP mannequin, operates utilizing a Combination-of-Specialists (MoE) structure. This method permits the mannequin to scale successfully whereas dealing with varied purposes corresponding to customer support automation, content material technology, and multilingual processing.
Actual-World Instance
DeepSeek V3 ensures that responses stay concise, informative, and well-structured, making it best for broad NLP purposes.
3. DeepSeek R1-Zero: Reinforcement Studying With out Supervised Tremendous-Tuning
DeepSeek R1-Zero takes a singular method. It’s educated solely by reinforcement studying with out counting on conventional supervised fine-tuning. Whereas this methodology ends in robust reasoning capabilities, the mannequin might sometimes generate outputs that lack fluency and coherence.
Actual-World Instance
Enter: “Describe the method of volcanic eruption.”
Anticipated Output: “Volcanic eruptions happen when magma rises beneath the Earth’s crust because of intense warmth and strain. The magma reaches the floor by vents, inflicting an explosion of lava, ash, and gases.”
DeepSeek R1-Zero efficiently conveys basic scientific ideas however typically lacks readability or mixes language components.
Mannequin Structure: How They Differ
1. DeepSeek V3’s Combination-of-Specialists (MoE) Structure
The Combination-of-Specialists (MoE) structure makes giant language fashions (LLMs) extra environment friendly by activating solely a small portion of their parameters throughout inference. DeepSeek-V3 makes use of this method to optimize each computing energy and response time.
DeepSeek-V3 builds on DeepSeek-V2, incorporating Multi-Head Latent Consideration (MLA) and DeepSeekMoE for quicker inference and decrease coaching prices. The mannequin has 671 billion parameters, however it solely prompts 37 billion at a time. This selective activation reduces computing calls for whereas sustaining robust efficiency.

MLA improves effectivity by compressing consideration keys and values, decreasing reminiscence utilization with out sacrificing consideration high quality. In the meantime, DeepSeek-V3’s routing system directs inputs to probably the most related specialists for every job, stopping bottlenecks and enhancing scalability.
Not like conventional MoE fashions that use auxiliary losses to steadiness knowledgeable utilization, DeepSeek-V3 depends on dynamic bias adjustment. This methodology ensures specialists are evenly utilized with out decreasing efficiency.
The mannequin additionally options Multi-Token Prediction (MTP), permitting it to foretell a number of tokens concurrently. This improves coaching effectivity and enhances efficiency on advanced duties.
For instance, if a person asks a coding-related query, DeepSeek-V3 prompts specialists specialised in programming whereas protecting others inactive. This focused activation makes the mannequin each highly effective and resource-efficient.
2. Architectural Variations Between DeepSeek R1 and R1-Zero
DeepSeek R1 and DeepSeek R1-Zero profit from the MoE framework however diverge of their implementation.
DeepSeek R1
Employs full MoE capabilities whereas dynamically activating specialists based mostly on question complexity.
Makes use of reinforcement studying (RL) and supervised fine-tuning for higher readability and logical consistency.
Incorporates load balancing methods to make sure no single knowledgeable turns into overwhelmed.
DeepSeek R1-Zero
Makes use of an identical MoE construction however prioritizes zero-shot generalization quite than fine-tuned job adaptation.
Operates solely by reinforcement studying, optimizing its capacity to sort out unseen duties.
Displays decrease preliminary accuracy however improves over time by self-learning.
Coaching Methodology: How DeepSeek Fashions Study
DeepSeek R1 and DeepSeek R1-Zero use superior coaching strategies to enhance the educational of enormous language fashions (LLMs). Each fashions apply modern methods to spice up reasoning abilities, however they observe completely different coaching approaches.
1. DeepSeek R1: Hybrid Coaching Method
DeepSeek R1 follows a multi-phase coaching course of, combining reinforcement studying with supervised fine-tuning for max reasoning capacity.
Coaching Phases:
Chilly Begin Section: The mannequin first fine-tunes on a small, high-quality dataset created from DeepSeek R1-Zero’s outputs. This step ensures clear and coherent responses from the beginning.
Reasoning Reinforcement Studying Section: Giant-scale RL improves the mannequin’s reasoning abilities throughout completely different duties.
Rejection Sampling and Tremendous-Tuning Section: The mannequin generates a number of responses, retains solely the proper and readable ones, after which undergoes additional fine-tuning.
Numerous Reinforcement Studying Section: The mannequin trains on quite a lot of duties, utilizing rule-based rewards for structured issues like math and LLM suggestions for different areas.

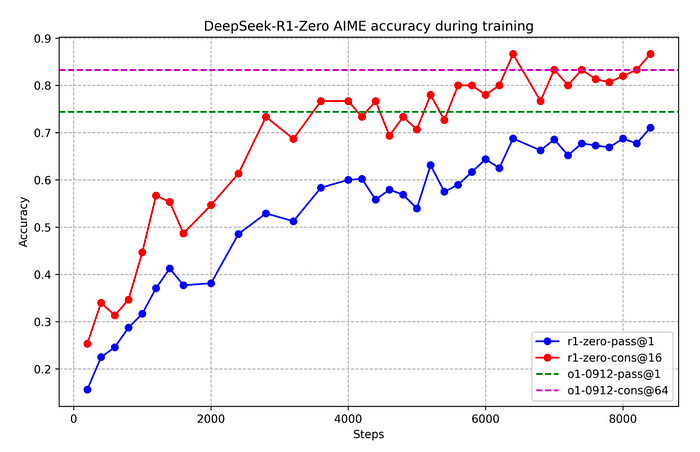
2. DeepSeek R1-Zero: Pure Reinforcement Studying
DeepSeek R1-Zero depends fully on reinforcement studying, eliminating the necessity for supervised coaching information.
Key Coaching Methods:
Reinforcement Studying Solely: It learns fully by reinforcement studying, utilizing a technique referred to as Group Relative Coverage Optimization (GRPO), which simplifies the method by eradicating the necessity for crucial networks.
Rule-Based mostly Rewards: It follows predefined guidelines to calculate rewards based mostly on accuracy and response format. This method reduces useful resource use whereas nonetheless delivering robust efficiency on varied benchmarks.
Exploration-Pushed Sampling: It explores completely different studying paths to adapt to new situations, resulting in improved reasoning abilities.

Overview of Coaching Effectivity and Useful resource Necessities
DeepSeek R1
Useful resource Necessities: It wants extra computing energy as a result of it follows a multi-phase coaching course of, combining supervised and reinforcement studying (RL). This additional effort improves output readability and coherence.
Coaching Effectivity: Though it consumes extra assets, its use of high-quality datasets within the early levels (cold-start part) lays a robust basis, making later RL coaching more practical.
DeepSeek R1-Zero
Useful resource Necessities: It makes use of a cheaper method, relying solely on reinforcement studying. It makes use of rule-based rewards as a substitute of advanced critic fashions, which considerably lowers computing prices.
Coaching Effectivity: Regardless of being extra easy, it performs properly on benchmarks, proving that fashions will be educated successfully with out in depth supervised fine-tuning. Its exploration-driven sampling additionally improves adaptability whereas protecting prices low.
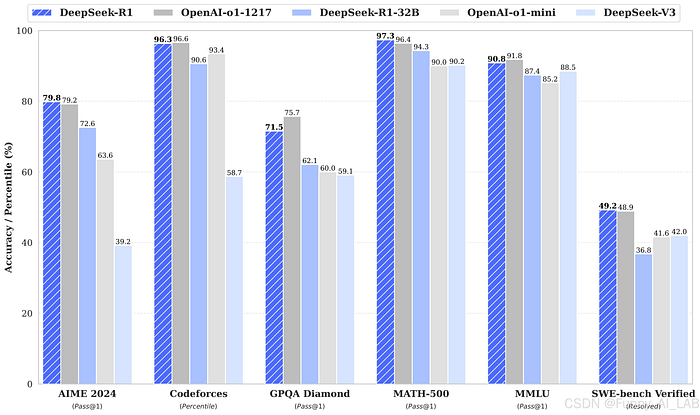
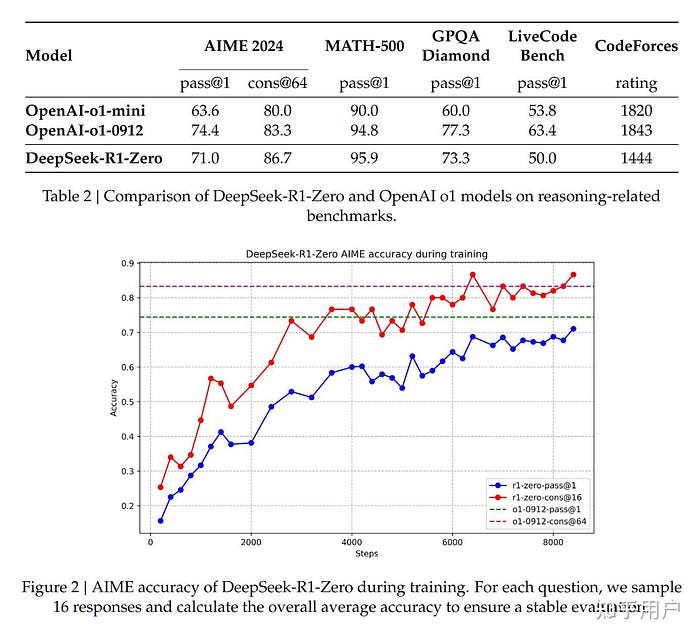
Efficiency Benchmarks: How They Evaluate
BenchmarkDeepSeek R1DeepSeek R1-Zero
AIME 2024 (Cross@1)79.8% (Surpasses OpenAI’s o1-1217)15.6% → 71.0% (After coaching)
MATH-50097.3% (Matches OpenAI fashions)95.9% (Shut efficiency)
GPQA Diamond71.5percent73.3%
CodeForces (Elo)2029 (Beats 96.3% of people)Struggles in coding duties
DeepSeek R1 excels in reasoning-intensive duties, whereas R1-Zero improves over time however begins with decrease accuracy.
The best way to Use DeepSeek Fashions with Hugging Face and APIs
You’ll be able to run DeepSeek fashions (DeepSeek-V3, DeepSeek-R1, and DeepSeek-R1-Zero) utilizing Hugging Face and API calls. Observe these steps to arrange and run them.
1. Operating DeepSeek-V3
Step 1: Clone the Repository
Run the next instructions to obtain the DeepSeek-V3 repository and set up the required dependencies:
git clone
cd DeepSeek-V3/inference
pip set up -r necessities.txt
Step 2: Obtain Mannequin Weights
You’ll be able to obtain the mannequin weights from Hugging Face. Exchange <model_name> with DeepSeek-V3 or DeepSeek-V3-Base:
huggingface-cli repo obtain <model_name> –revision primary –local-dir /path/to/DeepSeek-V3
Transfer the downloaded weights to /path/to/DeepSeek-V3.
Step 3: Convert Mannequin Weights
Run the next command to transform the mannequin weights:
python convert.py –hf-ckpt-path /path/to/DeepSeek-V3 –save-path /path/to/DeepSeek-V3-Demo –n-experts 256 –model-parallel 16
Step 4: Run Inference
Use this command to work together with the mannequin in real-time:
torchrun –nnodes 2 –nproc-per-node 8 generate.py –node-rank $RANK –master-addr $ADDR –ckpt-path /path/to/DeepSeek-V3-Demo –config configs/config_671B.json –interactive –temperature 0.7 –max-new-tokens 200
2. Operating DeepSeek-R1
Step 1: Set up and Run the Mannequin
Set up Ollama and run DeepSeek-R1:
ollama run deepseek-r1:14b
Step 2: Create a Python Script
Create a file referred to as take a look at.py and add the next code:
import ollama
model_name = ‘deepseek-r1:14b’
query = ‘The best way to clear up a quadratic equation x^2 + 5*x + 6 = 0’
response = ollama.chat(mannequin=model_name, messages=[
{‘role’: ‘user’, ‘content’: question},
])
reply = response[‘message’][‘content’]
print(reply)
with open(“OutputOllama.txt”, “w”, encoding=“utf-8”) as file:
file.write(reply)
Step 3: Run the Script
Guarantee Ollama is put in, then run:
pip set up ollama
python take a look at.py
3. Operating DeepSeek-R1-Zero
Step 1: Set up Required Libraries
Set up the OpenAI library to make use of the DeepSeek API:
pip set up openai
Step 2: Create a Python Script
Create a file referred to as deepseek_r1_zero.py and add the next code:
from openai import OpenAI
consumer = OpenAI(api_key=“<DeepSeek API Key>”, base_url=“https://api.deepseek.com”)
messages = [{“role”: “user”, “content”: “What is the capital of France?”}]
response = consumer.chat.completions.create(
mannequin=“deepseek-r1-zero”,
messages=messages
)
content material = response.decisions[0].message.content material
print(“Reply:”, content material)
messages.append({‘position’: ‘assistant’, ‘content material’: content material})
messages.append({‘position’: ‘person’, ‘content material’: “Are you able to clarify why?”})
response = consumer.chat.completions.create(
mannequin=“deepseek-r1-zero”,
messages=messages
)
content material = response.decisions[0].message.content material
print(“Rationalization:”, content material)
Step 3: Run the Script
Exchange <DeepSeek API Key> along with your precise API key, then run:
python deepseek_r1_zero.py
You’ll be able to simply arrange and run DeepSeek fashions for various AI duties!
Closing Ideas
DeepSeek’s newest fashions—V3, R1, and R1-Zero—convey important developments in AI reasoning, NLP, and reinforcement studying. DeepSeek R1 dominates structured reasoning duties, V3 gives broad NLP capabilities, and R1-Zero showcases modern self-learning potential.
With rising adoption, these fashions will form AI purposes throughout training, finance, healthcare, and authorized tech.


{kind=link}